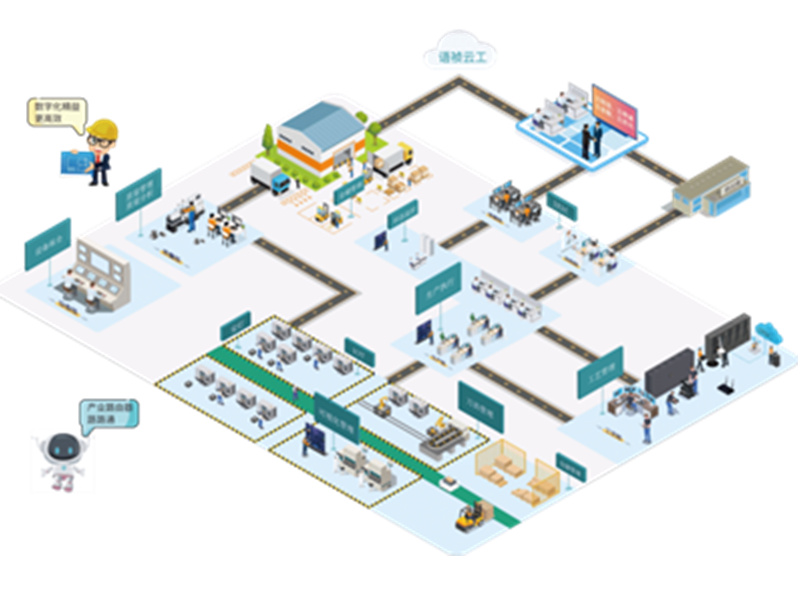
工业4.0的一个主要方面是获取和分析大数据,将数据转化为可操作的信息,并使系统能够自行做出决策。尽管存在新技术,但大多数制造企业仍使用剪贴板和纸张来收集数据和信息。在很多情况下,多达90%的数据最终孤立的滞留在现场。若希望从工业4.0中获益,这将带来一定的挑战。
好消息是新技术可以在这方面提供帮助,用户只需采取几个简单的步骤,就可以为数据转换做好准备,包括访问更多数据、进行边缘计算、清理数据,对数据进行情境化处理以及标准化通用数据结构。
获取更多数据是工业4.0的重要组成部分。工业的运营环境非常复杂,涉及数百种不同的协议、通信介质和传统设备的知识。数字化转型的实现必须是自下而上的实施,首先要优化运营技术(OT)。这需要以新的态度来保持系统的开放性、互操作性和安全性。第一步是以有效的方式获取所有的数据——能够在需要时从任何地方轻松访问数据。
MQTT的发布/订阅功能可简化通信,并有助于将轮询转移至网络边缘。图片来源:Inductive Automation
数据访问的主要障碍之一是传统软件许可模式,它对每个标签或用户收费。这些模式无法扩展,阻碍了增长。此外,工业应用一直是封闭的、专有的,并且功能和连接性也有限制。今天,我们需要从根本上无限制的、开放的新模式。这些新模式可以释放新的扩展机会和更大的可扩展性。
另一个挑战是新智能传感器和设备与现有旧设备融合之间的平衡。拥有同时支持两者的基础设施非常重要。它归结为一个关键概念:架构的变更。不再通过通讯协议将旧设备连接到应用,而是将设备与基础设施连接起来。需要提供一种即插即用、可靠且可扩展的OT解决方案,以满足运营人员的需求。
开放和可互操作的架构
这是一种基于消息队列遥测传输(MQTT)的新架构。MQTT是一种发布/订阅协议,启用了面向消息的中间件体系结构。在信息技术(IT)领域,这不是一个新概念;长期以来,企业服务总线(ESB)一直通过类似的总线的基础架构来集成应用程序。MQTT在异常事件发生时,设备数据会发布到本地或云端的MQTT服务器。应用程序订阅MQTT服务器以获取数据,这意味着无需连接到终端设备本身。MQTT具有以下优点:
●开放标准/可互操作(OASIS标准和Eclipse开放标准(TAHU));
●设备与应用分离;
●事件触发报告;
●需要的带宽很少;
●传输层安全;
●远程发起连接(仅出站;无入站防火墙规则);
●状态感知;
●数据单一来源;
●自动识别标签;
●数据缓冲(存储和转发);
●即插即用功能。
如何获得新的架构?答案是边缘计算和协议转换。假设有10个Modbus设备要连接到监控和数据采集(SCADA)系统。用户可以部署一个支持Modbus和MQTT的边缘网关,以使轮询更接近可编程逻辑控制器(PLC)。这样,用户就能够以更快的速度轮询更多信息,并在数值发生变化时将数值发布到中央MQTT服务器。还可以将SCADA连接并订阅MQTT服务器以获取数据,而不是直接连接到终端设备。这是确保SCADA系统面向未来的重要一步。当用户购买支持MQTT的传感器或升级设备时,SCADA无需了解终端设备即可获得数据访问权限。
帮助系统了解数据
用户不仅需要访问数据,还需要确保数据有效,具有上下文信息,并且是通用结构的一部分(如果适用)。这是使用分析和机器学习之前的重要步骤。系统只有了解数据,才能正确使用数据。通常,新的传感器和设备已经具有这些功能。但是,对于老旧设备并非如此。有数百种需要映射和扩展的不同轮询协议。大多数PLC的寻址方案都不容易理解。这些映射通常存在于SCADA中,但是仍然缺少上下文知识,或者包含无效数据,或者不是标准数据结构。
完成此步的最佳位置是连接到PLC的边缘网关。它需要具有清理数据、数据情境化和支持数据结构功能的软件。
让我们从清理数据开始。假设有一个传感器连接到PLC,有时信号会丢失。当信号丢失时,PLC中的数值将降为0。但在某些时候,数值可能确实为0,但如果最后一个数值是50,那现在的数值就可能不是0。在这种情况下,需要要查看数据变化以确定是否应该忽略当前值。使用该逻辑设置计算标签,可以解决此问题。在与其它系统共享数据之前,请务必在最接近源头的位置确认数据的有效性。
另一个关键步骤是为数据提供上下文。例如,在用户的Modbus PLC上,有一个参考地址为40001的标签。在SCADA系统中,会将其映射到某个标签,例如“环境温度”。如果仅有这个数据,那无法知道温度是摄氏度还是华氏度,以及高、低限是多少。如果没有上下文,数据分析和机器学习模型可能会提供错误的数据。
使用能够提供名称、比例、工程单位、工程上下限、文档和工具提示等信息的边缘网关,将为其它系统提供关键信息,以便于更好地理解基础数据。
标准化通用数据结构
最后一步是在整个企业范围内,标准化通用数据结构。由于每个站点的数据可能不同,并且很难找到通用的数据模型,因此通常会忽略此步骤。分析包和机器学习模型要求对于通用对象采用相同的数据结构。用户不希望为每个站点创建不同的分析或机器学习模型。这超出了单个数据点的范畴,是已知对象的数据点的集合。
重要的是调查每个站点以找到一个通用的模型,并使用支持用户定义类型(UDT)的边缘网关。这意味着调整每个站点的数据以适应模型,这可能包括缩放、计算标签、转换等。这样数据在表面上看起来是相同的结构,同时隐藏了背后的复杂性。
通过设置新的运营架构,解决将大数据导入基础架构的问题。在访问数据之前,用户无法进行分析和机器学习,因此数据必须有效并且具有上下文以便于理解。利用这种新的思维方式和基础架构,用户可以通过一些小的步骤和调整来实现先进技术带来的潜在好处。